汇编学习
本文基于x86汇编,例子丰富,可放心观看。
先来看一段用于计算阶乘的简单的程序:
1int fac(int n) {2 int ret = 1;34 for (int i = 2; i <= n; i++) {5 ret = ret * i;6 }78 return ret;9}可以通过 godbolt 网站得到其汇编代码:
xxxxxxxxxx191fac(int):2 push rbp3 mov rbp, rsp4 mov DWORD PTR [rbp-20], edi5 mov DWORD PTR [rbp-4], 16 mov DWORD PTR [rbp-8], 27 jmp .L28.L3:9 mov eax, DWORD PTR [rbp-4]10 imul eax, DWORD PTR [rbp-8]11 mov DWORD PTR [rbp-4], eax12 add DWORD PTR [rbp-8], 113.L2:14 mov eax, DWORD PTR [rbp-8]15 cmp eax, DWORD PTR [rbp-20]16 jle .L317 mov eax, DWORD PTR [rbp-4]18 pop rbp19 ret通过网站贴心的对比功能,可以猜测各部分的作用(当然笔者是在一定基础上写的笔记,故这里可能对初学者引起困惑,但不妨看下去):
开头
xxxxxxxxxx21push rbp ; 保存栈帧2mov rbp, rsp ; 函数栈空间连续变量定义与传参
xxxxxxxxxx31mov DWORD PTR [rbp-20], edi ;edi 为参数 n 的值,放到栈中[rbp-20]这个位置上2mov DWORD PTR [rbp-4], 1 ;定义ret=1, 放到栈中[rbp-4]的位置3mov DWORD PTR [rbp-8], 2 ;定义i=2,放到栈中[rbp-8]的位置循环
1jmp .L2 ; 先开始判断 i <= n2.L3: ; 循环体内容3mov eax, DWORD PTR [rbp-4] ; 将ret移动到寄存器eax中4imul eax, DWORD PTR [rbp-8] ; 将eax乘上i5mov DWORD PTR [rbp-4], eax ; 将eax移动到ret6add DWORD PTR [rbp-8], 1 ; i++7.L2: ; 判断语句8mov eax, DWORD PTR [rbp-8] ; 将i移动到寄存器eax9cmp eax, DWORD PTR [rbp-20] ; 比较eax的值与n的大小10jle .L3 ; 若小于则继续循环返回
xxxxxxxxxx31mov eax, DWORD PTR [rbp-4] ; 将ret内容移动到eax2pop rbp ; 栈中取出rbx,即销毁栈帧3ret ; 退出函数执行
下面会详细地引入汇编的各个概念,希望大家能够对这些代码有更清晰的认识。
储存与寻址
现代x86处理器有8个32位通用寄存器(寄存器大小写不敏感):
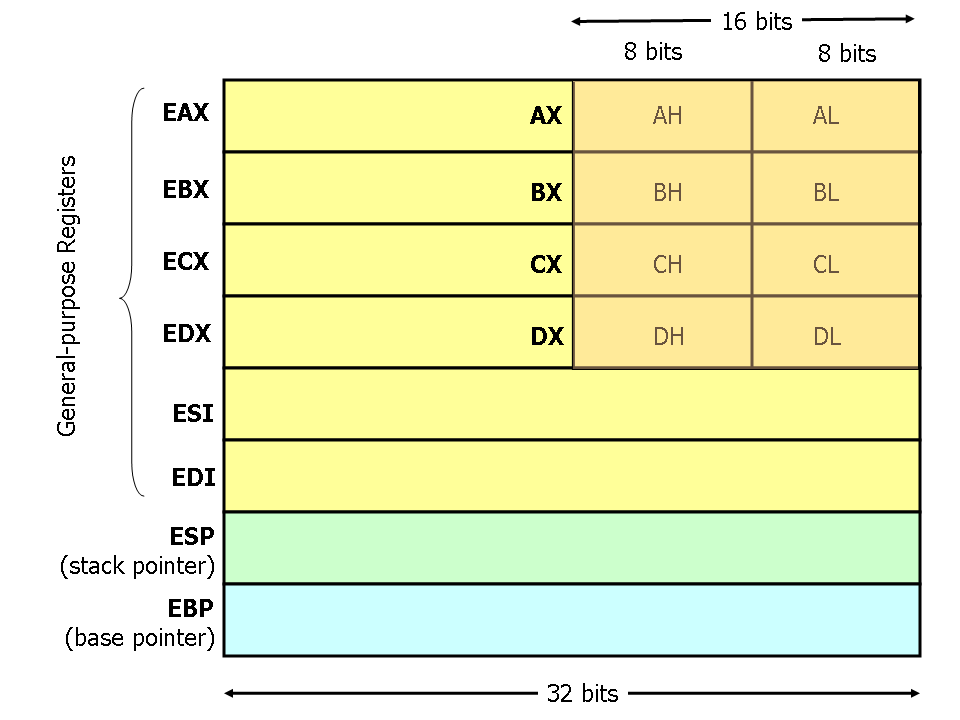
ESP 与 EBP 用于特殊用途,EAX、EBX、ECX 与 EDX 寄存器可以使用子节(subsection),例如 EAX 的低16位称为 AX,AX 的高8位与低8位称为 AH 与 AL,有时处理问题使用这些寄存器更加方便(如字符处理)。
另外在汇编语言中,内存主要分为四个区域:
1.代码段:该区域包含可执行程序的指令代码,通常是只读的,并且无法被修改。
2.数据段:该区域用于存储全局变量、静态变量和常量等数据,可以被读取和修改,包含 .data 段、.bss 段两部分。
3.堆栈段:当程序创建新的函数或者子程序时,这些函数和子程序的参数以及局部变量都会被保存在堆栈段的空间中。栈上的变量是动态分配的,在函数调用结束后,栈上的空间也会被自动释放。x86的栈向下生长,即栈顶 esp 内存地址小于栈底 ebp。
4.堆段:这是一个连续未被占用的空间,用于存储动态分配的内存。程序员可以手动通过malloc等方式来申请和释放堆上的内存空间。

静态存储
使用 .DATA 可以声明静态数据区域(类似于C中的全局变量),在此之后可使用 DB、DW、DD 来声明一个、两个和四个字节的存储位置,按照顺序声明的位置在内存中是连续的。另外在x86汇编语言中,数组仅允许声明一维的。
可以使用 DUP 指令来重复给定次数的表达式来声明数组,例如 4 DUP(2) 等价于 2,2,2,2,除此之外还可使用字符串字面值来初始化数组。
例:
xxxxxxxxxx71.DATA 2var DB 64 ; 声明1字节的数据,初始值为643var2 DW ? ; 声明2字节的数据,不初始化4 DD 10 ; 声明数据区域但是不命名5Z DD 1, 2, 3 ; 声明4字节的长度为3的数组, 初始化为1,2,3,Z+8位置数据的值为36bytes DB 10 DUP(?) ; 声明1字节的长度为10的数组,不初始化7str DB 'hello',0 ; 定义长度为6的字符串,初始化为`hello`的字符串的ascii码,最后一位为0另外对于在 C 中定义的全局变量,编译器会加入一些列伪指令,如下面程序:
xxxxxxxxxx31int a[100000000] = {1, 2, 3};2long long k = 1;3char b[] = "qiqi";会编译为:
xxxxxxxxxx261 .globl a2 .data3 .align 324 .type a, @object5 .size a, 4000000006a:7 .long 18 .long 29 .long 310 .zero 39999998811 12 .globl k13 .align 814 .type k, @object15 .size k, 816k:17 .quad 118 19 .globl b20 .type b, @object21 .size b, 522b:23 .string "qiqi"24 .text25 .globl fac(int)26 .type fac(int), @function其中 .align 为设置对齐方式,.long .quad .string 为数据定义伪操作,.globl 为定义全局符号,.type 用来指定一个符号的类型是函数类型(@function)或者是对象类型(@object)。
注意 .data 段与 .bss 段是不同的,这里留个坑,有空再填。
内存寻址
现代x86处理器能够寻址32位宽内存地址,例如上面声明变量后,使用名称就可以引用该内存区域(事实上被替换为32位内存地址)。除此之外,x86提供了另外一种方案:将两个寄存器和一个带符号常量加起来计算内存地址,其中一个寄存器可以数乘2、4或8,如 [esi+4*ebx]。
寻址模式可以用于多种指令,下面使用 mov 命令演示寄存器与内存之间移动数据。mov 命令需要两个参数,第一个参数是移动到的位置,第二个参数是源位置。(注:这里的移动实际上是赋值)
xxxxxxxxxx41mov eax, [ebx] ; 将(储存在ebx中地址位置的值)移动到eax2mov [var], ebx ; 将ebx的值移动到常量var储存的地址位置3mov eax, [esi-4] ; 将地址位置为[esi-4]的存储数据的值移动到eax4mov [esi+4*eax], cl ; 将cl的内容移动到地址位置为[esi+4*eax]的值下面是 不合法 的操作:
xxxxxxxxxx21mov eax, [ebx-ecx] ; 寄存器变量只能加法2mov [eax+esi+edi], ebx ; 寻址最多支持两个寄存器的运算指定长度
如果使用 mov [ebx], 2,无法判断是将多少位的整数2移动到 [ebx] 的位置,引起歧义,故需要指定长度 BYTE PTR、WORD PTR 与 DWORD PTR,分别代表1、2、4字节的数据。
例如 int a[10]; void set(int n) { a[n] = n; } 对应的汇编代码为:
xxxxxxxxxx131a:2 .zero 403set(int):4 push rbp5 mov rbp, rsp6 mov DWORD PTR [rbp-4], edi7 mov eax, DWORD PTR [rbp-4]8 cdqe ; 符号位的拓展9 mov edx, DWORD PTR [rbp-4]10 mov DWORD PTR a[0+rax*4], edx ; a[n] = n;11 nop12 pop rbp13 ret指令集
这里只介绍一些常用的指令,如果想要查阅所有指令,可以看本文末 [2] 的开发手册。
方便介绍参数的类型,我们使用下面的符号来代表各种类型。
| 符号 | 含义 |
|---|---|
<reg32> | 任意32位寄存器(EAX、EBX、ECX、EDX、ESI、EDI、ESP 或 EBP) |
<reg16> | 任意16位寄存器(AX、BX、CX 或 DX) |
<reg8> | 任意8位寄存器(AH、BH、CH、DH、AL、BL、CL 或 DL) |
<reg> | 任意寄存器 |
<mem> | 内存地址(例如 [eax]、[var + 4] 与 dword ptr [eax+ebx]) |
<con32> | 任意32位常量 |
<con16> | 任意16位常量 |
<con8> | 任意8位常量 |
<con> | 任意8、16、32位常量 |
数据操作
mov指令:将其第二个参数(即寄存器内容、内存内容或常量)的数据复制到其第一个参数(即寄存器或内存)所引用的位置。特别地,mov无法将内存内容移动到内存内容,需要先放到寄存器来间接移动。语法:
x
1mov <reg>,<reg>2mov <reg>,<mem>3mov <mem>,<reg>4mov <reg>,<const>5mov <mem>,<const>push指令:参数入栈。实现原理为将esp减4后将操作数放到[esp]的32位位置。语法:
x
1push <reg32>2push <mem>3push <con32>pop指令:出栈到参数中。实现原理先移动[esp]后将esp增加4。语法:
x
1pop <reg32>2pop <mem>lea指令:将第二个参数(内存位置)的地址放入到第一个参数(寄存器)。该指令不加载内存位置的内容,只计算有效地址并将其放入寄存器。语法:
x
1lea <reg32>,<mem>
有些人认为 lea 是可以被取代的,因为下面代码是等价的:
xxxxxxxxxx21mov ebx, offset Value 2lea ebx, Value 然而 lea 并非只是 mov 的附庸,其实有一些好处:
lea指令效率高。指令本身是单时钟周期的,且由 CPU 的 AGU(地址生成单元,address generation unit)执行,不会与上下文算数逻辑产生流水相关,且 AGU 与 ALU 并行执行,提高吞吐量。
lea可以巧妙地模拟三元算数逻辑。intel 指令集中不存在许多 risc 机器支持的三元算数逻辑,如 ARM 中的
add r0,r1,r2,而lea的第二个参数可以支持两寄存器的加法。例如要计算两寄存器的和,不想破坏原来的值,可以使用
lea ebx,[eax+edx],如果使用add,无法使用一条指令完成。
另外还有一种有趣的取址方式,下面C代码:
xxxxxxxxxx31 int *b = &a;2 int **c = &b;3 int ***d = &c;对应的汇编代码为:
xxxxxxxxxx51 mov QWORD PTR [rbp-16], OFFSET FLAT:a2 lea rax, [rbp-16]3 mov QWORD PTR [rbp-24], rax4 lea rax, [rbp-24]5 mov QWORD PTR [rbp-8], rax可以看到对于一维指针,编译器直接使用了 OFFSET FLAT:a 来进行取址,还是有点意思的。
控制语句
x86会维护一个指令指针的32位寄存器(IP),指向内存中当前指令的起始位置,执行完语句后该指针递增,指向下一条指令。IP 寄存器无法直接操作,只能通过控制语句进行隐式更改。
jmp指令:跳转到指定标签。可以使用
<label>:来插入标签,这样就可以直接输入标签名称来跳转,而不是指令对应的地址。语法:
jmp <label>jcondition指令:条件跳转。这组指令是基于一组条件状态的条件跳转,这些条件状态存储在一个称为 machine status word 的特殊寄存器中。机器状态字的内容包括有关上次执行的算术运算的信息。
语法:
x
1je <label> ; 相等时跳转2jne <label> ; 不相等时跳转3jz <label> ; 上一个结果为0时跳转4jg <label> ; 大于时跳转5jge <label> ; 大于等于时跳转6jl <label> ; 小于时跳转7jle <label> ; 小于等于时跳转cmp指令:修改 machine status word。大部分条件跳转的上一条指令为
cmp指令。x
1cmp <reg>,<reg>2cmp <reg>,<mem>3cmp <mem>,<reg>4cmp <reg>,<con>call、ret指令:实现函数的调用与返回。call指令首先将当前代码位置入栈,然后跳转到参数对应的代码位置。相比于jmp,call保存了ret后要返回的位置。语法:
x
1call <label>2ret例如C语言程序:
xxxxxxxxxx41void a() {}2int b() { return 0; }34void d() { a(); b(); }编译后得到:
xxxxxxxxxx201a():2push rbp3mov rbp, rsp4nop5pop rbp6ret7b():8push rbp9mov rbp, rsp10mov eax, 011pop rbp12ret13d():14push rbp15mov rbp, rsp16call a()17call b()18nop19pop rbp20ret其中
nop为空指令,用于进行指令的对齐(有些CPU对跨边界的指令需要额外的周期来做译码工作)。
算数操作
略,比较简单
调用约定
由于汇编语言比较底层,对于栈与参数的传递都需要手动进行,故通常使用通用的调用约定来保证函数传参、返回值的一致性。
这里以C调用约定来讲解:C调用约定很大程度上依赖于使用硬件支持的栈。它基于push, pop, call和ret指令。子程序参数在栈上传递。寄存器保存在栈上,子例程使用的局部变量放在栈的内存中。在大多数处理器上实现的绝大多数高级过程语言都使用了类似的调用约定。
调用约定分为两组规则。第一组规则由函数的调用者使用,第二组规则由函数的编写者(被调用者)遵守。需要强调的是,这种调用约定不同于驼峰命名法之类的约定,如果不按照统一的调用约定,程序可能直接运行错误。
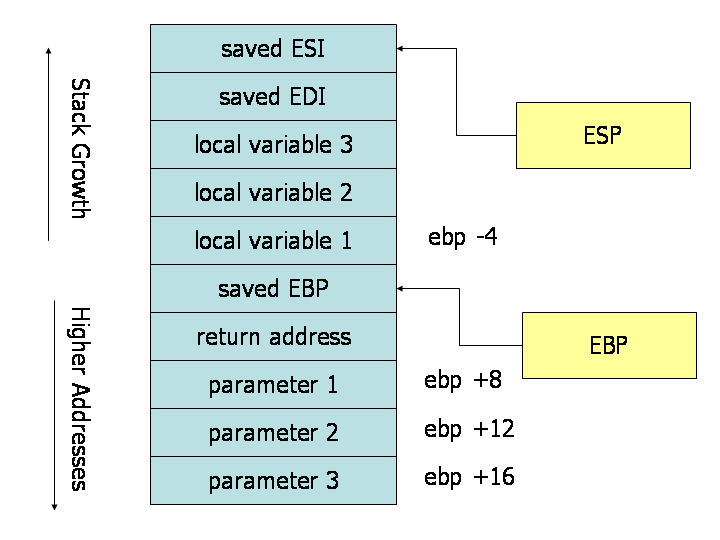
上面的图像描述了在执行具有三个参数和三个局部变量的函数调用期间堆栈的内容。堆栈中描述的单元是32位宽的内存位置,因此单元的内存地址间隔为4字节。第一个参数位于距基指针8字节的偏移处。调用指令将返回地址放置在堆栈上的参数上方(基指针下方),从而导致从基指针到第一个参数的额外4字节偏移。当使用 ret 指令从函数返回时,它将跳转到存储在堆栈上的返回地址。
调用方:
- 保存寄存器的内容。函数可能会对作为参数的寄存器进行修改,如果调用者仍然需要其值,需要提前入栈。
- 参数应倒序传入。
- 函数的返回值可以在
eax中获取。
函数:
开头需要进行固定的一些操作:
将
EBP入栈,然后将ESP的值复制到EBP:xxxxxxxxxx21push ebp2mov ebp, esp这是用来维护调用方的栈与当前函数所在的栈。
然后在栈上创建空间以分配局部变量,注意栈是向小内存生长,故声明多少字节的局部变量,
esp就需要递减多少。在返回前,还需要进行下面的操作:
恢复调用者保存的已修改寄存器的旧值(可以通过出栈到寄存器来恢复)。
释放局部变量,通常写法为
mov esp ebp。恢复调用者的
ebp,通常写法为pop ebp。最后使用
ret返回。
特别地,可以使用 leave 指令整合倒数二、三步,其等价于:
xxxxxxxxxx21 mov ebp, esp2 pop ebp下面是一个调用含多个参数的函数的例子,其C程序为
xxxxxxxxxx81void long_func(int a, int b, int c, int d, int e, int f, int g, int h, int i, int j) {2 a = i;3 b = j;4}5int d() {6 int a = 1, b = 2;7 long_func(1,2,3,a,5,6,b,8,9,10);8}对应的汇编为:
xxxxxxxxxx291long_func(int, int, int, int, int, int, int, int, int, int):2 push ebp3 mov ebp, esp4 mov eax, DWORD PTR [ebp+40]5 mov DWORD PTR [ebp+8], eax6 mov eax, DWORD PTR [ebp+44]7 mov DWORD PTR [ebp+12], eax8 nop9 pop ebp10 ret11d():12 push ebp13 mov ebp, esp14 sub esp, 1615 mov DWORD PTR [ebp-4], 116 mov DWORD PTR [ebp-8], 217 push 1018 push 919 push 820 push DWORD PTR [ebp-8]21 push 622 push 523 push DWORD PTR [ebp-4]24 push 325 push 226 push 127 call long_func(int, int, int, int, int, int, int, int, int, int)28 add esp, 4029 ud2可以看到通过参数倒序入栈来进行传递,函数内通过 [ebp+x] 来访问参数。
本文以 署名-非商业性使用-相同方式共享 发布。
参考资料:
[1]. Guide to x86 Assembly 相当有用的教程,简明扼要地解释了各种语句的含义。
[2]. Intel® 64 and IA-32 Architectures Software Developer Manuals 开发手册,查阅使用,不建议直接看,例如 [1] 中使用‘gory’一次来形容它。
[3]. Embedded System: Memory Layout when using Assembly Language 汇编语言的内存结构。
[4]. 汇编语言中PTR的含义及作用 详细写明 PTR 的作用,以及 MOV 与 LEA 的关系。
[5]. gcc - Intel assembly syntax OFFSET